
For decades, the search bar has been the gateway to the internet. We learned to think in keywords. If you wanted to find a recipe for lasagna, you typed “lasagna recipe.” If you needed a flight to London, you searched “cheap flights London to NYC.” It was a transactional relationship: you provided the specific terms, and the database provided the exact match.
But the internet has grown beyond simple text. It is now a sprawling universe of images, audio, video, complex documents, and unstructured data. The way we interact with this data is undergoing a seismic shift. We are moving away from the rigid world of exact matches and entering the fluid realm of semantic understanding. At the heart of this transformation lies a technological marvel that is quietly reshaping how machines understand the world: the vector database.
While the term might sound like something out of a sci-fi novel, it is rapidly becoming a standard component of the modern technology stack. However, with this new power comes a critical question for developers and architects: Is this the right tool for the job? Understanding when to deploy a vector database is just as important as knowing how to deploy one.
The Hidden Geometry of Intelligence
To understand why vector databases are gaining traction, we first have to look at how modern artificial intelligence actually “thinks.” Traditional databases store data in rows and columns. A row is a record; a column is a field. A relational database knows that a user named “John Doe” is not the same entity as a user named “Jane Doe,” even if they share the same name. It relies on strict definitions and schemas.
Vector databases operate on a completely different principle. Instead of storing structured data, they store information as “vectors”–mathematical representations of data points in a multi-dimensional space.
Imagine you are standing in a vast, open field. You have a map, and every piece of information you need is represented by a specific landmark. A “cat” might be a tree located to the north. A “dog” might be a rock located slightly to the east. Even though a cat and a dog are different, they are close to one another on this map.
This is the essence of a vector embedding. When a Large Language Model (LLM) processes a piece of text, it converts that text into a long list of numbers–a vector. The meaning of the text is encoded in the relationship between these numbers. If you ask the model to compare two sentences, it doesn’t read the words; it calculates the mathematical distance between the two vectors.
If the vectors are close together, the concepts are semantically similar. If they are far apart, they are different.
This geometry allows for a type of search that traditional databases simply cannot perform. It allows for “semantic search.” Instead of asking for “apple pie,” a vector database can understand that you might be looking for “apple tart” or “fruit pie,” even if those words don’t appear in the document. It understands the intent behind the query, not just the keywords.
 Photo by Steve Johnson on Pexels
Photo by Steve Johnson on Pexels
This capability is revolutionary, but it comes with a cost. It requires a database engine designed to handle high-dimensional geometry, perform complex calculations on the fly, and index these mathematical representations efficiently. That is the specific job of a vector database.
From “Exact Match” to “Close Enough”: The Game Changer
The primary driver for adopting vector databases is the rise of Generative AI and Retrieval-Augmented Generation (RAG). If you are building a chatbot that can answer questions based on your company’s internal documents, a standard search engine won’t cut it.
Consider a scenario where a legal firm needs to review thousands of case files for a specific legal precedent. A traditional search might return results containing the word “precedent” or “court,” but it might miss a relevant document that discusses the “Supreme Court ruling” or “judicial decision” because those keywords aren’t present. The user would miss critical information.
A vector database, however, can understand that “Supreme Court ruling” and “judicial decision” are semantically related. It retrieves the relevant documents, feeds them into the LLM, and allows the AI to provide a nuanced, accurate answer based on the actual content of the files.
This capability extends far beyond text. It is transforming how we interact with unstructured data. E-commerce platforms are using vector search to offer recommendations that feel uncannily personal. Instead of suggesting “Running shoes” because you bought them before, a vector database can understand that you bought “Yoga mats” and “witnessed a sudden interest in wellness,” and thus recommend “Resistance bands” or “mat towels.”
Furthermore, vector databases are becoming the backbone of content moderation and sentiment analysis. By analyzing the vector representation of user comments, systems can detect hate speech, sarcasm, or emotional distress with a nuance that simple keyword filters fail to capture.
For developers, this means the ability to build applications that feel “alive” and intelligent. It bridges the gap between the raw power of an LLM and the specific, factual knowledge of an organization’s private data.
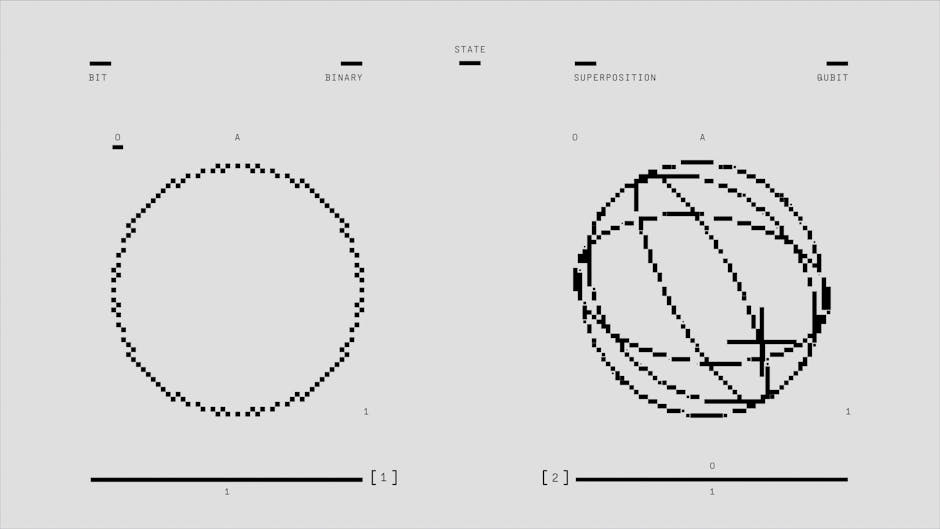 Photo by Google DeepMind on Pexels
Photo by Google DeepMind on Pexels
The Trap of Over-Engineering
While vector databases offer incredible power, they are not a silver bullet for every data problem. In the world of software architecture, there is a rule of thumb: don’t use a sledgehammer to crack a nut. Introducing a vector database into your stack adds significant complexity, cost, and latency.
The most common mistake is applying vector search to structured, transactional data where exact matching is sufficient. If you are building a traditional e-commerce site that sells blue widgets and red widgets, and you need to store user profiles, order history, and inventory levels, a robust relational database like PostgreSQL or MySQL is still the superior choice.
Why? Because relational databases are battle-tested. They offer ACID compliance, ensuring that money is never lost during a transaction and data is never corrupted. They provide strong consistency guarantees that are essential for banking, inventory management, and user authentication.
Vector databases, by contrast, are often optimized for “approximate” results. They trade a tiny bit of accuracy for massive speed gains using algorithms like HNSW (Hierarchical Navigable Small World). While this is perfect for finding the “most similar” document, it is not ideal for financial ledgers or user credentials.
There is also the issue of overhead. Storing vectors requires significantly more storage space than storing text. Processing vectors requires specialized hardware and complex indexing structures. If your application doesn’t actually need to understand the meaning of the data, but only needs to locate it by ID, you are adding unnecessary bloat to your system.
If you are building a simple blog with a search bar that only needs to find posts containing specific tags or phrases, a standard database with a full-text search index is perfectly adequate. Do not force a vector database into a scenario where a simple SQL query would do the job.
The Hybrid Approach: Mixing the Best of Both Worlds
The most sophisticated applications often don’t choose between the old and the new; they integrate them. This is where the true power of vector databases shines: they don’t have to replace your existing data infrastructure; they can work alongside it.
A powerful architecture involves a hybrid approach. You keep your relational database for all transactional operations–storing user data, managing sessions, and handling financial transactions. You then use a vector database as a specialized “semantic search layer” on top of your unstructured data.
For example, a media company might have a relational database that stores the metadata of its videos (duration, upload date, genre, uploader ID). This data is perfect for filtering and sorting. However, to help users discover content, the company uses a vector database to analyze the actual video frames and audio transcripts. When a user searches for “vintage travel footage from the 1980s,” the system combines the precise filtering of the relational database (to ensure the video is from the correct decade) with the semantic understanding of the vector database (to find the specific aesthetic and content of the footage).
This separation of concerns allows each database to do what it does best. It allows architects to scale their systems independently. They can optimize the relational database for high-concurrency write operations, while scaling the vector database for massive read throughput and complex similarity searches.
 Photo by Google DeepMind on Pexels
Photo by Google DeepMind on Pexels
Ready to Upgrade Your Search Strategy?
The transition to vector databases is more than just a technical upgrade; it is a shift in how we conceptualize data retrieval. It moves us from a world of rigid, keyword-based retrieval to one of fluid, meaning-based understanding.
For organizations dealing with unstructured data, complex user interactions, or cutting-edge AI applications, vector databases are no longer optional–they are essential. They provide the bridge that allows artificial intelligence to access and utilize the vast troves of human knowledge that have been locked away in documents, audio, and video for decades.
However, this technology should be approached with caution. It requires a thoughtful architectural strategy. Before diving in, ask yourself: Is my problem one of exact matching or semantic understanding? Am I trying to retrieve a specific record, or am I trying to find relevant information?
By answering these questions honestly, you can determine whether a vector database is the right tool for your specific mission. When used correctly, it is a transformative technology that unlocks new possibilities for innovation and user experience. When used incorrectly, it is simply an expensive and complex addition to the stack.
The future of search is semantic. The question is: is your organization ready to make the leap?
Suggested External Resources for Further Reading:
- Pinecone.io: “What is a Vector Database?” (A comprehensive introduction to the concepts and use cases).
- Weaviate.io: “What is Vector Search?” (Excellent visual explanations of how vector search works).
- LangChain: “Retrieval-Augmented Generation” (Technical deep dive into how vector databases are used with LLMs).
- Wikipedia: “Vector Space Model” (The academic foundation behind how computers understand text similarity).
Suggested Internal Links for Your Site:
- “How to Optimize SQL Queries for Performance” (Context: contrasting with the overhead of vector search).
- “The Complete Guide to Large Language Models” (Context: explaining the AI context).
- “Designing Scalable Cloud Architectures” (Context: discussing hybrid systems and infrastructure).


